这一节来学习 Vulkan 多线程渲染的设计理念和执行过程,学习过程中可以深入理解 Vulkan 中 Queue 和 Command Buffer 的关系与作用。
1 Vulkan 多线程设计理念
Vulkan 不仅仅是图形 API,而是一个面向图形和计算的编程接口。支持 Vulkan 的设备可以是 GPU,也可以是 DSP 或者固定功能的硬件。
Vulkan 中的计算模型主要基于并行计算,因此支持多线程是 Vulkan 设计的核心理念之一。
为了减少 Vulkan 内部因为互斥同步等操作造成的卡顿问题,Vulkan 内部默认认为对任何资源的访问不存在多线程竞争,所有的资源同步操作由应用开发者去负责,因为对资源的访问和使用没有人比应用开发者自己更加清楚。Vulkan 称之为外部同步(external synchronization)。
因为这个原因,资源管理和线程同步工作成为编写 Vulkan 程序的最大难点之一。想要让 Vulkan 多线程正常运行,你需要做大量的工作。当然,换来的是 Vulkan 有了更加干净的线程模型以及比其它 CG API 高得多的性能。
2 Instances、Devices 和 Queues
Vulkan 多线程模型与几个概念紧密相关,我们再次回顾这些概念:
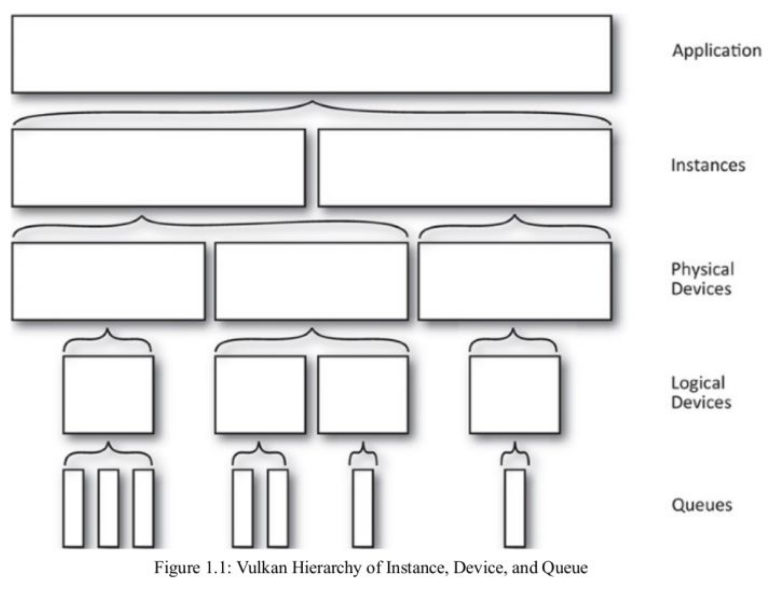
- Instances 可以看做是应用的子系统,从逻辑上把 Vulkan 与应用程序上下文中的其他逻辑隔开。Instances 可以看做是 Vulkan 的上下文,它会跟踪所有状态,从逻辑上把所有支持 Vulkan 的设备整合在一起。
- Physical devices 和 Logical device 都是 Devices,Physical devices 通常代表一个或者多个支持 Vulkan 的硬件设备,这些设备具有特定功能,可以提供一系列 Queues。图形显卡、加速器、DSP 等都可以是 Vulkan 的 Physical devices。Logical device 是 Physical devices 的软件抽象,用于预订一些硬件资源。
- Queues 可以理解为一个“GPU 线程”,它是实现 Vulkan 多线程的关键元素之一,用于响应应用的请求,大部分时间,应用都在与其进行交互。
三者之间的层次关系如下图所示:
3 Queues 和 Command Buffer
3.1 Queues
Queue 代表一个 GPU 线程,Vulkan 设备执行的就是提交到 Queues 中的工作。物理设备中 Queue 可能不止一个,每一个 Queue 都被包含在 Queue Families 中。
Queue Families 是一个有相同功能的 Queues 的集合,它们的性能水平和对系统资源的访问是相同的,并且在它们之间数据传输工作没有任何成本(同步之外)。
一个物理设备中可以存在多个 Queue Families,不同的 Queue Families 有不同的特性。相同 Queue Families 中的 Queues 的功能相同,并且可以并行运行。如下图:
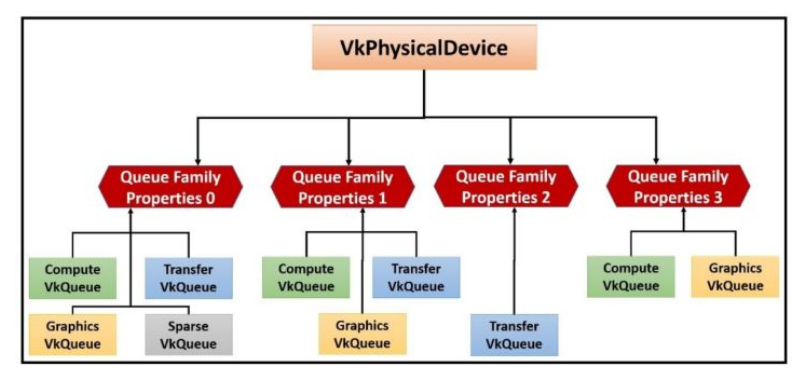
按照 Queue 的能力,可以将其划分为:
Graphics(图形):该系列中的 Queues 支持图形操作,例如绘制点,线和三角形。
Compute(计算):该系列中的 Queues 支持诸如 computer shader 之类的计算操作。
Transfer(传输,拷贝):该系列中的 Queues 支持传输操作,例如复制缓冲区和图像内容。
Sparse binding(稀疏绑定):该系列中的 Queues 支持用于更新稀疏资源(sparse resource)的内存绑定操作。
3.2 Command Buffer
传统 CG API 是单线程的,性能的提升只能依赖于 CPU 主频的提高。能有的优化方案也不外乎主线程和渲染线程分开,或者某些资源的异步加载、离线处理。
Vulkan 为了充分发挥 CPU 多核多线程的作用,引入了 command buffer 的概念。多个线程可以同时协作,每个 CPU 线程都可以往自己的 command buffer 中提交渲染命令,然后统一提交到对应的 Queue 中,大大提高了 CPU 的利用率。
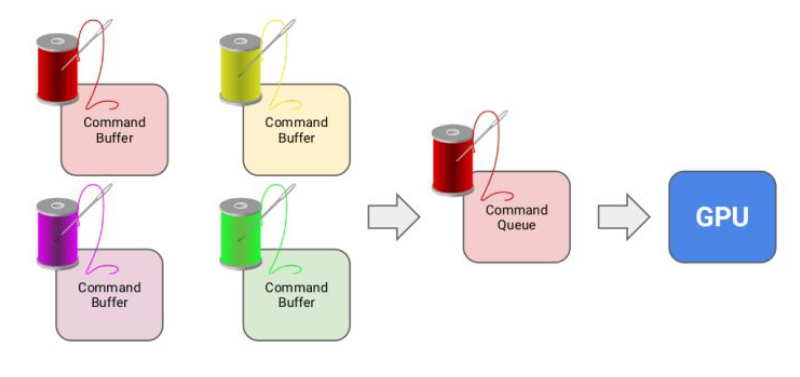
应用在绘制时会提交一系列绘制命令给 GPU 驱动,但是这些绘制命令不会立刻被执行,而是被简单的添加到 Command Buffer 的末尾。
在其他 CG APIs 中,驱动程序在应用不感知的情况下,把 API 调用翻译成 GPU command 并储存在 command buffer 中,最终提交给 GPU 处理。command buffer 的创建和销毁都由驱动负责。
而在 Vulkan 中,你需要自己从 Command Buffer Pool 中申请 command buffer,将想要记录的命令放入 command buffer 中。
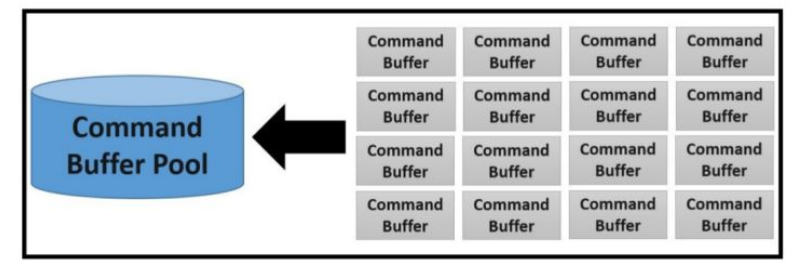
Command Buffer 可以记录(Record)很多命令,比如设置状态、绘制操作、数据拷贝等等,如下图所示:
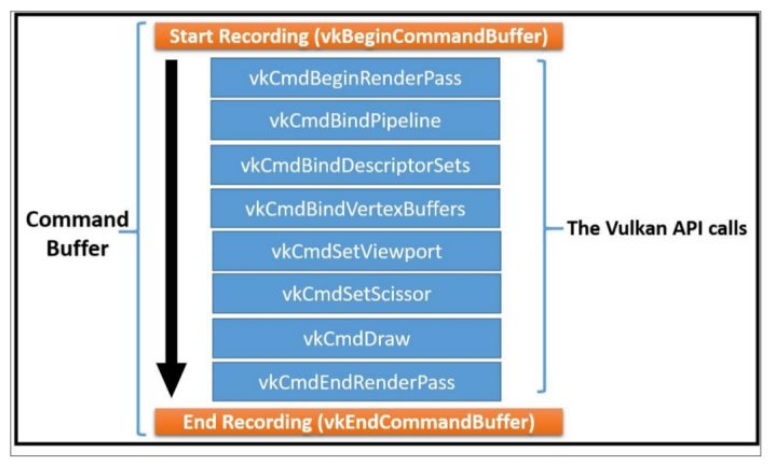
理论上,一个线程可以把 Command 记录到多个 Command Buffer 中,多个线程也可以共享同一个 Command Buffer,但是一般不鼓励多个线程共享一个 Command Buffer。
Vulkan 的关键设计原则之一就是做到高效的多线程。想实现这一点,应用程序要注意因为资源竞争导致的多线程彼此阻塞。因此,每个线程最好有一个或者多个 Command Buffer,不要尝试共享一个。另外,Command Buffer 由 Command Buffer Pool 分配,应用可以为每一个线程创建一个 Command Buffer Pool,让各个工作线程从 Command Buffer Pool 中分配 Command Buffer,无需参与竞争。
3.3 Command Buffer 生命周期
从 Command Buffer 创建开始,会经历不同的状态,如下图所示:
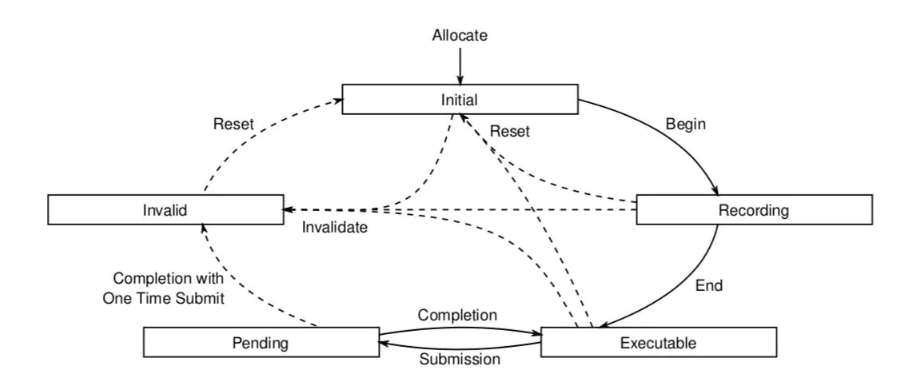
- Initial 状态:在
Command-Buffer刚刚创建时,它就是处于初始化的状态。从此状态,可以达到Recording状态,另外,如果重置之后,也会回到该状态。 - Recording 状态:调用
vkBeginCommandBuffer方法从Initial状态进入到该状态。一旦进入该状态后,就可以调用vkCmd*等系列方法记录命令。 - Executable 状态:调用
vkEndCommandBuffer方法从Recording状态进入到该状态,此状态下,Command-Buffer可以提交或者重置。 - Pending 状态:把
Command-Buffer提交到Queue之后,就会进入到该状态。此状态下,物理设备可能正在处理记录的命令,因此不要在此时更改Command-Buffer,当处理结束后,Command-Buffer可能会回到Executable状态或者Invalid状态。 - Invalid 状态:一些操作会使得
Command-Buffer进入到此状态,该状态下,Command-Buffer只能重置、或者释放。
4 Vulkan 同步机制
4.1 显式同步操作
Vulkan 把同步的操作交给了我们的应用程序(external synchronization),绝大多数的 Vulkan 命令根本不提供同步,需要应用自己负责。Vulkan 给应用提供了同步原语,帮助应用进行同步操作。
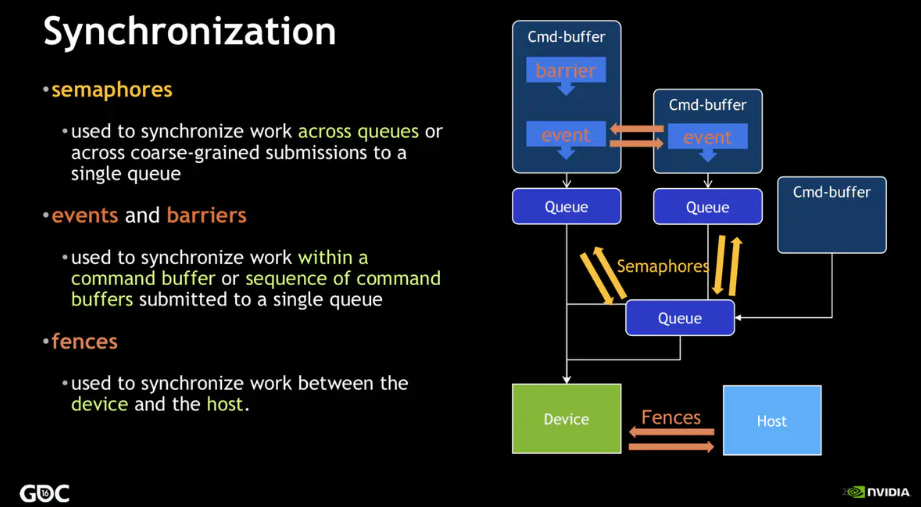
Vulkan 中主要有四种同步原语(synchronization primitives):
Fences:最大颗粒度的同步原语,用来保证物理设备和应用程序之间的同步,比如说向
Queue中提交了Command-Buffer后,具体的执行交由物理设备去完成了,这是一个异步的过程,而应用程序如果要等待执行结束,就要使用Fence机制。因此Fences给 CPU 端提供了一种方法,可以使其知道 GPU 或者其他 Vulkan Device 什么时候把提交的工作全部做完。Semaphores:颗粒度比 Fences 更小一点,主要是用来向
Queue中提交Command-Buffer时实现同步。比如说某个Command-Buffer-B在执行的某个阶段中需要等待另一个Command-Buffer-A执行成功后的结果,同时Command-Buffer-C在某阶段又要等待Command-Buffer-B的执行结果,那么就应该使用Semaphore机制实现同步;此时Command-Buffer-B提交到Queue时就需要两个VkSemaphor,一个表示它需要等待的Semaphore,并且指定在哪个阶段等待;一个是它执行结束后发出通知的Semaphore。Events:颗粒度更小,可以用于 Command Buffer 之间的同步工作
Barriers:Vulkan 流水线(Pipeline)阶段内用于内存访问管理和资源状态移动的同步机制
4.2 隐式执行顺序
在没有同步原语的情况下,Vulkan 的执行顺序其实是有一定的潜规则的:
- Command Buffer 中的 Command,先记录的先执行
- 先提交的 Command Buffer 先执行
- 同一个 Queue 中,一起提交的 Command Buffer1 和 Command Buffer2 按照下标的顺序执行,即 Command Buffer1 先执行
4.3 Barriers
Barriers 需要开发者了解渲染管线的各个阶段,能清晰的把握管线中每个步骤对资源的读写顺序。
Vulkan 中将 Pipeline 的各个阶段定义为:
- TOP_OF_PIPE_BIT
- DRAW_INDIRECT_BIT
- VERTEX_INPUT_BIT
- VERTEX_SHADER_BIT
- TESSELLATION_CONTROL_SHADER_BIT
- TESSELLATION_EVALUATION_SHADER_BIT
- GEOMETRY_SHADER_BIT
- FRAGMENT_SHADER_BIT
- EARLY_FRAGMENT_TESTS_BIT
- LATE_FRAGMENT_TESTS_BIT
- COLOR_ATTACHMENT_OUTPUT_BIT
- TRANSFER_BIT
- COMPUTE_SHADER_BIT
- BOTTOM_OF_PIPE_BIT
对应于管线流程图:
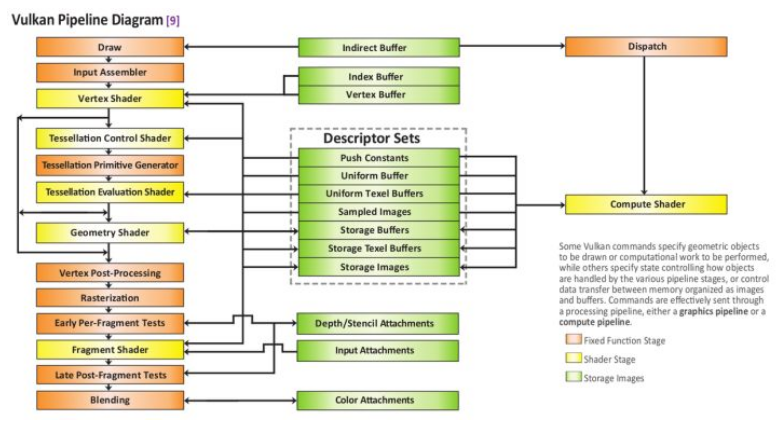
假设我们有个两个渲染管线 P1 和 P2,P1 会通过 Vertex Shader 往 buffer 写入顶点数据,P2 需要在 Compute Shader 中使用这些数据。
如果使用 fence 去同步,我们的流程应该是这样:P1 的 Command 提交后,P2 通过 fence 确保 P1 的操作已经被全部执行完,再开始工作。
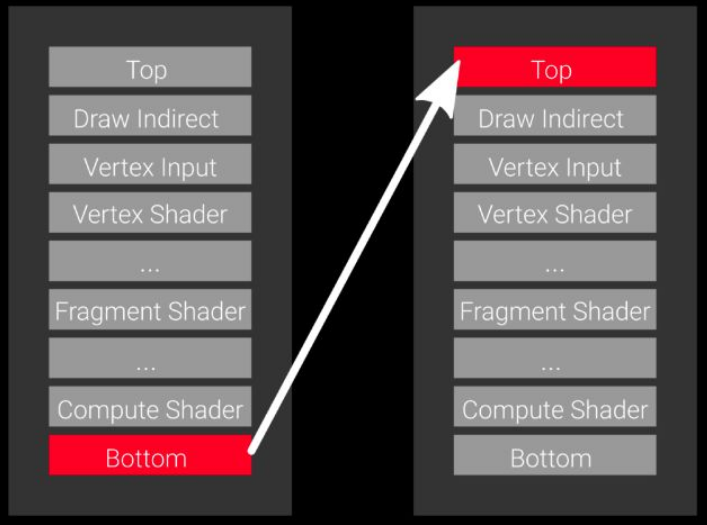
但是这种大颗粒度的同步操作无疑造成了耗时操作:P1 的数据在 Vertex Shader 阶段就已经准备好了,我们为什么要等到它所有操作执行完再开始?P2 平白多等待了很长时间,而且在这个期间 P2 的其他阶段并没有使用到 P1 的数据,也是可以同步执行的。
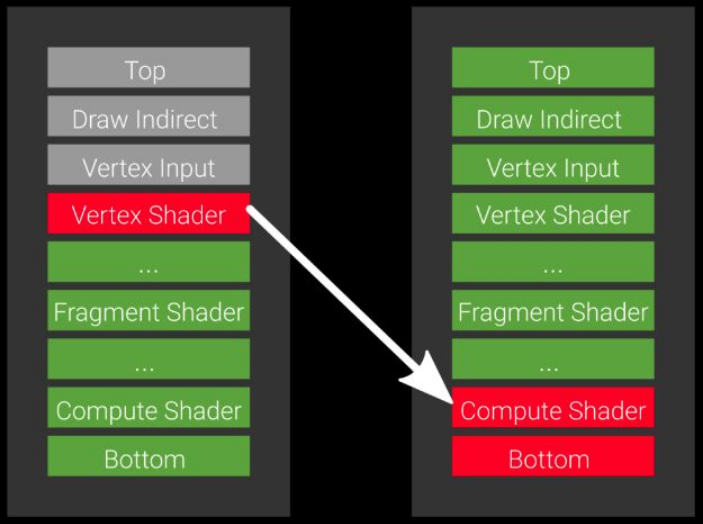
Barriers 的引入完全解决了这个问题,我们只需要告诉 Vulkan,我们在 P2 的 Compute Shader 阶段才会等待 P1 Vertex Shader 里面的数据,其他阶段并不关心,可以同步进行。
5 具体用法
接下来总结上述 4 种组件的具体用法。首先回顾 Vulkan 中重要的组件及其工作流程:
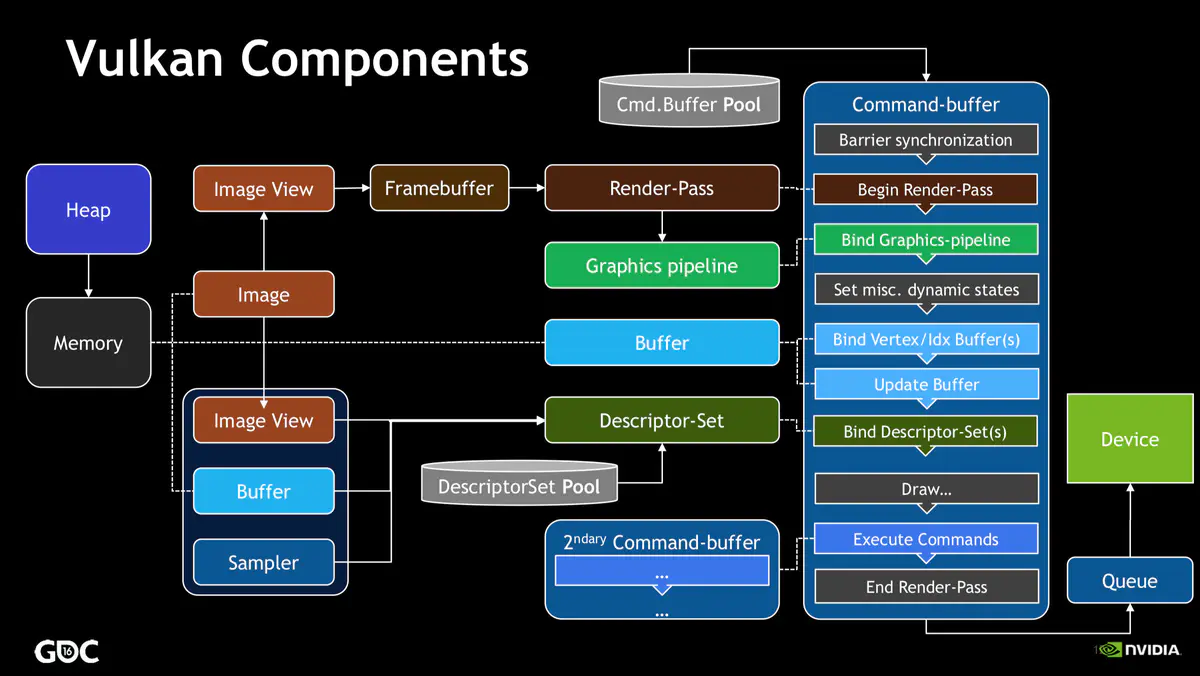
在 Vulkan 的 API 中有一些固定的调用套路 :
- 要创建某个对象,先提供一个包含创建信息的对象。
- 创建时通过传递引用的方式来传参。
5.1 Instance 组件
在 vkCreateInstance 函数中有个名为 VkInstanceCreateInfo 类型的参数,这就是包含了 VKInstance 要创建的信息:
1 | typedef struct VkInstanceCreateInfo { |
除此之外还需要创建一个 VkApplicationInfo 对象:
1 | typedef struct VkApplicationInfo { |
下面是创建一个 instance 的代码:
1 | VkApplicationInfo app_info = {}; |
当每调用一个创建函数后,返回的类型都是 VkResult ,只要 VkResult 大于 0 ,那么执行就是成功的。
5.2 Device 组件
有了 Instance 组件,就可以创建 Device 组件了,按照调用的套路,肯定还会有一个 VkDeviceCreateInfo 的结构体表示 Device 的创建信息。
Device 具体指的是逻辑上的设备,可以说是对物理设备的一个逻辑上的封装,而物理设备就是 VkPhysicalDevice 对象。
在某些情况下,可能会具有多个物理设备,因此要先枚举一下所有的物理设备:
1 | uint32_t gpu_size = 0; |
在 vkEnumeratePhysicalDevices 方法中,传入的第二个参数为 GPU 的个数,第三个参数为 null,这样的一次调用会返回 GPU 的个数到 gpu_size 变量。
1 | vector<VkPhysicalDevice> gpus; |
当再一次调用 vkEnumeratePhysicalDevices 函数时,第三个参数不为 null,而是相应的 VkPhysicalDevice 容器,那么 gpus 会填充 gpu_size 个的 VkPhysicalDevice 对象。
有了 VkPhysicalDevice 对象之后,可以查询 VkPhysicalDevice 上的一些属性,以下函数都可以查询相关信息:
- vkGetPhysicalDeviceQueueFamilyProperties
- vkGetPhysicalDeviceMemoryProperties
- vkGetPhysicalDeviceProperties
- vkGetPhysicalDeviceImageFormatProperties
- vkGetPhysicalDeviceFormatProperties
以 QueueFamilyProperties 为例,获得该属性的方法调用方式和获得 VkPhysicalDevice 数据方式一样,也是一个两次调用:
1 | // 第一次调用,获得个数 |
QueueFamilyProperties 的结构体含义如下:
1 | typedef struct VkQueueFamilyProperties { |
其中的 queueFlags 表示该 Queue 的能力,有的 Queue 是用来渲染图像的,还有的 Queue 是用来计算的,具体的 Flag 标识如下:
1 | typedef enum VkQueueFlagBits { |
接下来是创建一个 Device,在 VkDeviceCreateInfo 结构体中需要一个参数是 VkDeviceQueueCreateInfo ,因此要先创建 VkDeviceQueueCreateInfo,再创建 VkDeviceCreateInfo,最后调用 vkCreateDevice 创建一个 Device:
1 | // 创建 Queue 所需的相关信息 |
5.3 Queue 组件
完成了 Device 创建之后,Queue 的创建也简单多了,直接调用如下函数就好了:
1 | typedef void (VKAPI_PTR *PFN_vkGetDeviceQueue) |
完成了 Instance、Device、Queue 组件的创建之后,还有一件要做的事情就是释放它们,销毁组件。
按照先进后出的方式进行销毁,Instance 最先创建因此最后销毁,和 Device 相关联的 Queue 在 Device 销毁时就随之销毁了。
1 | // 销毁 Device |
5.4 Command Buffer 组件
在前面的学习中,我们已经创建了 Instance、Device、Queue 三个组件,并且知道了 Queue 组件是用来和物理设备沟通的桥梁,而具体的沟通过程就需要 Command-Buffer 组件,它是若干命令的集合,我们向 Queue 提交 Command-Buffer,然后才交由物理设备 GPU 进行处理。
5.4.1 创建 Command Pool
在创建 Command-Buffer 之前,需要创建 Command-Pool 组件,从 Command-Pool 中去分配 Command-Buffer 。还是老套路,我们需要先创建一个 VkCommandPoolCreateInfo 的结构体,结构体每个参数的释义还是要多参考官方的文档。
1 | // 创建 Command-Pool 组件 |
有几个参数需要注意:
queueFamilyIndex参数表示创建Queue时选择的那个queueFlags为VK_QUEUE_GRAPHICS_BIT的索引,从Command-Pool中分配的的Command-Buffer必须提交到同一个Queue中。flags有如下的选项,分别指定了Command-Buffer的不同特性:
1 | typedef enum VkCommandPoolCreateFlagBits { |
- VK_COMMAND_POOL_CREATE_TRANSIENT_BIT:表示该
Command-Buffer的寿命很短,可能在短时间内被重置或释放 - VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT:表示从
Command-Pool中分配的Command-Buffer可以通过vkResetCommandBuffer或者vkBeginCommandBuffer方法进行重置,如果没有设置该标识位,就不能调用vkResetCommandBuffer方法进行重置。
5.4.2 创建 Command Buffer
接下来就是从 Command-Pool 中分配 Command-Buffer,通过 VkCommandBufferAllocateInfo 函数。首先需要一个 VkCommandBufferAllocateInfo 结构体表示分配所需要的信息:
1 | typedef struct VkCommandBufferAllocateInfo { |
这里有个参数也要注意:
VkCommandBufferLevel指定Command-Buffer的级别。
有如下级别可以使用:
1 | typedef enum VkCommandBufferLevel { |
一般来说,使用 VK_COMMAND_BUFFER_LEVEL_PRIMARY 就好了。
具体创建代码如下:
1 | VkCommandBuffer commandBuffer[2]; |
5.4.3 Command Buffer 记录与提交命令
回顾上面的 Command Buffer 记录命令流程图:
在 vkBeginCommandBuffer 和 vkEndCommandBuffer 方法之间可以记录和渲染相关的命令,我们先不考虑中间的过程,直接创建提交。
首先,还是需要创建一个 VkCommandBufferBeginInfo 结构体用来表示 Command-Buffer 开始的信息:
1 | VkCommandBufferBeginInfo beginInfo = {}; |
这里要注意的参数是 flags ,表示 Command-Buffer 的用途:
1 | typedef enum VkCommandBufferUsageFlagBits { |
我们用的 VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT 表示该 Command-Buffer 只使用提交一次,用完之后就会被重置,并且每次提交时都需要重新记录。
直接调用 vkEndCommandBuffer 方法就可以结束记录,此时就可以提交了:
1 | vkEndCommandBuffer(commandBuffer[0]); |
接下来通过 vkQueueSubmit 方法将 Command-Buffer 提交到 Queue 上。同样的还是需要创建一个 VkSubmitInfo 结构体:
1 | typedef struct VkSubmitInfo { |
它的参数比较多,并且涉及到 Command-Buffer 之间的同步关系了,上面已经提到过 Semaphore 和 Fence 的相关内容。
如果只是简单的提交 Command-Buffer,那就不需要考虑 Semaphore 这些同步机制了,把相应的参数都设置为 nullptr,或者直接不设置也行,最后提交就好了,代码如下:
1 | // 简单的提交过程 |
以上就完成了 Command-Buffer 提交到 Queue 的过程,省略了 Semaphores 和 Fences 的同步机制,当然也可以把它们加上。
我们在 vkQueueSubmit 的最后一个参数设置为了 VK_NULL_HANDLE ,这是 Vulkan 中设置为 NULL 的一个方法(其实是设置了一个整数 0 ),也可以设置 Fence ,表示我们要等待该 Command-Buffer 在 Queue 执行结束,当 vkQueueSubmit 的最后参数传入 Fence 后,就可以通过 Fence 等待该 Command-Buffer 执行结束:
1 | // 创建 Fence |