本篇总结图形学相关知识点,提供之前笔记的索引,并补充部分内容,方便查找,将持续更新。
GPU 渲染管线
可以查看笔记【Real-Time Rendering】图形渲染管线 和 【Real-Time Rendering】GPU 管线
图形渲染管线是抽象的图像渲染流程,GPU 渲染管线是现代 GPU 对该流程的具体实现。
图形渲染过程中有哪些坐标空间?他们是如何进行变换的?具体的矩阵
包括模型空间、世界空间、观察空间、裁剪空间、NDC和屏幕空间
M 变换从模型空间到世界空间
V 变换从世界空间到观察空间
P 变换从观察空间到裁剪空间
透视除法从裁剪空间到 NDC
视口变换从 NDC 到屏幕空间
各种矩阵的推导查看笔记【光栅化渲染器】(三)变换与深度测试
变换过程中的坐标系哪些是左手系哪些是右手系,为什么会发生变化
模型空间和世界空间是什么坐标系不重要,描述的都是一样的世界,但观察空间就取决于我们的定义了,OpenGL 中模型、世界、相机坐标系使用的都是右手系,即沿 -Z 轴方向观察,经过投影之后变换到裁剪空间是左手系,因为在观察空间中,沿 -Z 方向观察,距离我们近的物体 Z 坐标更大,距离我们远的物体 Z 坐标更小,经过投影矩阵的变换,所有物体的 Z 坐标被变换到 -w 到 w 之间,其中较大的 Z 值 被映射到 -w,较小的 Z 值被映射到 w,也就是距离我们近的物体 Z 会更小,距离我们远的物体 Z 会更大,这正是左手坐标系的 Z 轴走向。
正交投影和透视投影有什么区别
正交投影的视锥体是一个立方体,进行的是平行投影,相当于只做了平移和缩放,透视投影的视锥体是一个四棱台,近大远小,本质上相当于利用 Z 坐标对其他坐标进行了缩放。
NDC 是什么
归一化设备坐标系,x 和 y 都是 -1 到 1 之间,Z 在 -1 到 1 (OpenGL)或 0 到 1 之间(DirectX),方便通过视口变换得到屏幕坐标。
视口变换的作用是什么,空间的维度是如何变化的
视口变换将 NDC 坐标变换到屏幕空间上,也叫屏幕映射,虽然屏幕坐标可以认为是二维的,但是依然保留了每个片段的深度。
顶点着色器的作用
顶点着色器用于进行顶点处理,必须完成的就是将顶点坐标变换到裁剪空间,也可以做顶点的着色、移动等处理。
片元和像素的区别
片元是像素的候选
逐顶点光照和逐片元光照
查看笔记【计算机图形学】(六)着色
光栅化的作用
生成片元。找到三角形覆盖哪些像素,生成对应的片元。
常用的光栅化算法
扫描线和边界函数算法,具体查看笔记【光栅化渲染器】(二)框架搭建和【光栅化渲染器】(九)改进光栅化
Phong 和 Blinn Phong 的区别,为什么这么改进
区别在于高光项的计算,改进的原因一方面在于计算量,另一方面因为视线方向可能和反射方向夹角大于 90 度,从而导致高光截断或者过渡不自然,而正常情况下半程向量和法线夹角不可能大于 90 度,从而使得高光过度更加自然。
走样产生的原因,如何解决
光栅化的走样和纹理走样
查看笔记【计算机图形学】(四)反走样和【计算机图形学】(七)纹理映射
MipMap 的作用、原理、如何确定使用哪一层
查看笔记【计算机图形学】(七)纹理映射
一般使用 ddx 和 ddy 确定使用的层级,ddx 和 ddy 可以快速求出像素某一属性的变化率,因为 GPU 在执行片段着色的时候不是逐像素进行的,是以 2 * 2 的块为单位执行的,每个 wrap 被分为 8 * 4 个线程组,每个像素快就被分配到一个包含 4 个线程的线程组执行,所以可以快速得到相邻像素某属性的变化率,通过计算相邻像素纹理坐标的差值可以得出:
- 相邻像素纹理坐标差值越大,说明纹理在屏幕上对应的空间越小,因此就使用越大的 mipmap 层级
- 相邻像素纹理坐标差值越小,说明纹理在屏幕上对应的空间越大,因此就使用更小的 mipmap 层级
更多细节可以查看在shader中计算贴图mipmap级别中的公式和代码
法线贴图的种类,优缺点
查看笔记【Real-Time Rendering】纹理总结第七部分
伽马校正是什么,为什么需要
查看笔记【RayTracer】(四)漫反射材质第三部分
HDR 和色调映射,常用的映射算法
查看笔记【Real-Time Rendering】基于图像的渲染技术总结第 10 部分
Shadow Map 的实现、缺点、有哪些改进
查看笔记【高质量实时渲染】实时阴影
PCF 和 PCSS
查看笔记【高质量实时渲染】实时阴影
常用的抗锯齿方法
查看笔记【Real-Time Rendering】图形渲染和视觉处理第三部分和【计算机图形学】(四)反走样
另外工业上目前在用的一些方法的详细原理和实现可以查看:
通常在项目中会将多种 AA 算法混合起来使用以达到更好的效果。
什么是模板测试
查看笔记【Real-Time Rendering】模板测试和深度测试
透明度混合和透明度测试
各种物体的的渲染顺序
顺序无关的透明渲染算法
查看笔记【Real-Time Rendering】图形渲染和视觉处理第 4 部分
compute shader 是干嘛的
在图形管线之外的,但可以将计算数据传入管线或回传给自己,实现利用 GPU 进行通用计算任务
渲染方程
经典渲染方程和实时渲染中的渲染方程(带 visibility 项)
BRDF 简介
描述入射光和出射光关系的函数,分为经验模型、物理模型和测量模型,各类常用的模型举例,以及各向同性各向异性
查看笔记【Real-Time Rendering】BRDF 总结
菲涅尔项 F0 的意义
F0 是基础反射率,与介质的折射率有关,可以代表物体本身的颜色,从 SG 模型的 Specular 纹理中得到或者从 MR 模型的 base color 纹理中采样再经过 metalic 插值得到
PBR 的原理
基于物理的渲染,关键在于能量守恒,菲涅尔项和 BRDF 的计算(cook-torrance 模型)
PBR 的计算需要哪些量
基础反射率 F0,粗糙程度,光线和法线夹角,观察方向和法线夹角
光线追踪和路径追踪
查看笔记【计算机图形学】(十一)Whitted 风格光线追踪、【计算机图形学】(十三)路径追踪、【高质量实时渲染】实时光线追踪
蒙特卡洛积分方法
延迟渲染的原理,对比正向渲染,延迟渲染的改进
查看笔记【Real-Time Rendering】延迟渲染总结
延迟渲染和 MSAA
查看笔记【Real-Time Rendering】延迟渲染总结
一些提高渲染效率的方法
固定视角渲染只渲染一次固定物体,剔除被 UI 遮挡的物体
双缓冲或者三重缓冲保持帧率稳定
其他查看笔记【Real-Time Rendering】渲染加速技术总结
如何优化 shader 代码
尽量避免分支语句、条件判断和循环,尽量减少纹理采样次数,减少复杂数学函数调用,少在片段着色器做矩阵运算,降低浮点数精度等
具体查看Shader中的代码优化原理分析
GLFW 的作用
用于创建窗口,创建 OpenGL 上下文、接收一些鼠标键盘事件的第三方库
所谓上下文是指保存了一系列的变量用来描述 OpenGL 此刻需要如何运行的信息,因为 OpenGL 本身就是一个非常庞大的状态机(State Machine) ,其状态通常被称为 OpenGL 上下文(Context),应用程序中可以创建多个不同的上下文,他们分别在各自的线程中使用。上下文之间共享纹理,缓冲区等资源,采用这中方案更为高效,因为它避免了反复切换上下文,或者大量修改渲染状态所造成的较大的开销。
GLAD 和 GLEW
对底层 OpenGL 接口的封装,可以让代码跨平台
DirectX 和 OpenGL
总结来说 OpenGL 只提供核心的渲染功能,至于窗口显示,设备输入处理等都需要第三方库,但 OpenGL 有良好的跨平台特性
DirectX 并不是一个单纯的图形API,它是由微软公司开发的用途广泛的API,它可让以 windows 为平台的游戏或多媒体程序获得更高的执行效率,加强 3d 图形和声音效果。
后处理方法
查看笔记【Unity Shader】(七)基础屏幕特效和【Unity Shader】(八)高级屏幕特效
NPR 基本原理、描边算法
利用深度和屏幕坐标算世界坐标
利用屏幕坐标得到 NDC 坐标,或者将纹理坐标映射到 NDC 坐标 -1 到 1 范围内,再乘以投影矩阵的逆矩阵得到投影前的坐标,记得除以 w 值进行坐标归一化,然后再乘以 V 矩阵的逆矩阵得到世界空间坐标
具体查看Unity根据深度值计算世界坐标
深度精度问题和 reversed-Z
延迟渲染具体实现
延迟渲染实现 AO
查看SSAO 屏幕空间环境光遮蔽(与延迟渲染的pass结合)
简单来说就是利用 G-Buffer 中的信息生成一张 AO 贴图,之后在渲染 Pass 中利用这张帖图乘到光照结果上即可
延迟渲染透明物体
Unity 有哪些管线
Unity 提供以下渲染管线:
- 内置渲染管线是 Unity 的默认渲染管线。这是通用的渲染管线,其自定义选项有限。
- 通用渲染管线 (URP) 是一种可快速轻松自定义的可编程渲染管线,允许您在各种平台上创建优化的图形。
- 高清渲染管线 (HDRP) 是一种可编程渲染管线,可让您在高端平台上创建出色的高保真图形。
- 可以使用 Unity 的可编程渲染管线 API 来创建自定义的可编程渲染管线 (SRP)。这个过程可以从头开始,也可以修改 URP 或 HDRP 来适应具体需求。
OpenGL 的渲染管线
和正常管线基本一致,具体查看OpenGL渲染管线
帧缓冲有哪些,什么是离屏渲染
帧缓冲包含颜色缓冲、深度缓冲和模板缓冲,离屏渲染就是将渲染结果存到自定义的帧缓冲中进行一些后处理,再将该缓冲中的内容发送到默认缓冲显示到屏幕上。
具体查看帧缓冲详解
BVH 划分维度造成的问题
对于走廊一样的场景,如果不沿着最长的维度分割,就会造成物体在某一个维度上被分开了,集中在一定范围内,但是其他维度上这些物体分布非常分散,导致最终的 AABB 会很大,每个节点的 AABB 都覆盖了很大的范围,并且各个 BVH 节点之间的 AABB 就会有很大的重合,导致 BVH 的加速效果不好。
纹理坐标到纹理的映射公式
直接上代码:
1 | // 纹理采样,使用重复寻址方式,等同于OpenGL的GL_REPEAT |
实例化渲染和批处理
参考:
Vulkan 中 Pass 和 SubPass 的关系
Vulkan学习笔记(四)厘清Pipeline和RenderPass的关系 - 知乎 (zhihu.com)
从 cache 角度讲 Mipmap 为什么比直接采样纹理效率高
首先影响采样效率的主要原因并不是在于纹理采样有多耗时,纹理采样主要是通过 TMU 模块进行执行的,TMU 模块是一种有限的硬件资源, 因此你采样更多(不一样的)纹理,就需要消耗更多的周期。这是因为当采样纹理的时候要加载纹理数据,TMU 会首先向 Texture Cache 中去加载,如果 Cache Miss 就会从 L2 加载到 Textuer Cache,如果 L2 也 Cache Miss,就会从 DRAM(显存) 中加载纹理,然后依次填充 L2 和 Texture Cache。
而我们知道从Thread 读到 Texture Cache 只需要几十个周期,而从 L2 向 DRAM 加载则需要几百个周期。在这些周期内,需要采样纹理的 Warp Scheduler 都需要被换出(swap out)。
更多可以查看更新一些GPU相关知识 - 知乎 (zhihu.com)
MSAA 是逐像素做 Z-test 还是逐 sample 做 Z-Test
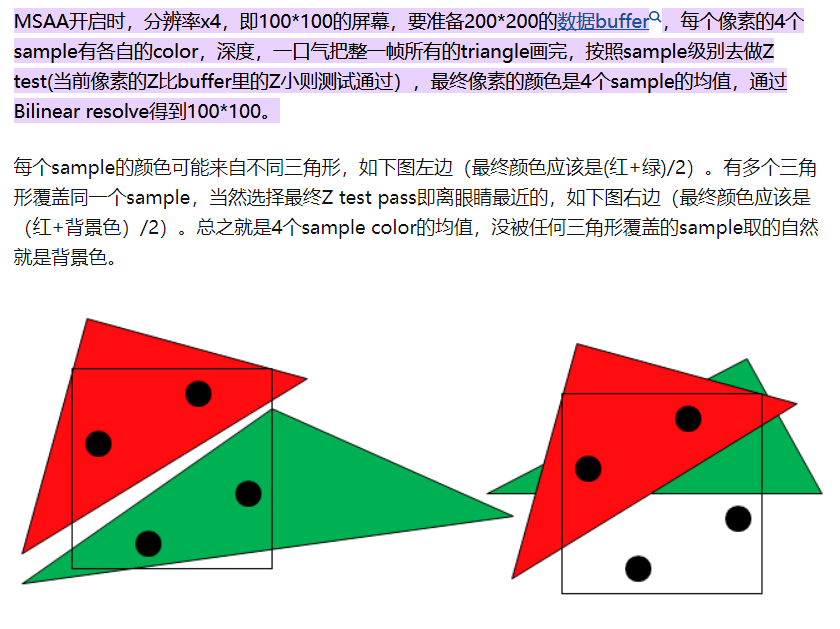
PBR 的核心是什么
关键在于能量守恒以及菲涅尔项的计算得到的直接光照,以及 IBL 得到的间接光照。实际上单单使用 Cook-Torrance 模型计算的光照结果并不比经验模型比如 Blinn-Phong 真实多少,关键在于间接光照的加持,才使得整个材质看起来更真实。
线性空间和 sRGB 是什么意思
所谓线性空间就是真实世界的亮度变化,但是显示器并不是线性的,显示伽马大约为 2.2,因此我们才要进行伽马校正(0.45 次幂)
sRGB 相当于是一个 gamma0.45 的空间,其中的颜色值可以认为已经经过了 0.45 次幂的伽马校正,因此可以直接显示
在 PBR 中,输入的纹理通常是 sRGB 的,因此我们要先将纹理值转换到线性空间(2.2 次幂)在进行着色计算,因为要想让画面真实,就应该在真实世界的线性空间进行计算,如果在 gamma0.45 空间计算真实世界的线性光照,画面肯定会显得不自然。
具体可以查看Gamma、Linear、sRGB