《深度探索C++对象模型》第四章重点梳理。主要内容包括:
- 调用不同成员函数的背后工作
- 虚函数详解
- 内联函数的背后工作
1 调用不同成员函数的背后工作
C++ 类中包括三种成员函数:非静态成员函数、静态成员函数和虚函数。这三种成员函数被调用时,编译器会进行不同的背后工作。
1.1 非静态成员函数
C++的设计准则之一就是:非静态成员函数必须至少和一般的非成员函数有相同的效率。所以 C++ 的做法就是在非静态成员函数被调用时,编译器将其转化为一般的非成员函数,并传入一个对象的指针。
假设有一个成员函数:
1 | float Point3d::magnitude() const |
下面是转化步骤:
- 改写函数的 signature(函数原型)以安插一个额外的参数到成员函数中,作为对对象成员的存取管道,该额外参数即为 this 指针,如果成员函数是 const,则传入参数也为 const
- 将对每一个成员变量的存取操作改为经由 this 指针的存取操作
- 将成员函数重写为一个外部非成员函数,并对函数名进行编码,使其有一个独一无二的内部名称
转化后的的函数如下:
1 | extern float magnitude_7Point3dFv(const Point3d* this) |
对函数的调用:
1 | Point3d* ptr = new Point3d(); |
也被转化为:
1 | magnitude_7Point3dFv(ptr); |
1.2 静态成员函数
静态成员函数类似于非静态成员函数,编译器同样将其转化为一般的外部非成员函数,唯一的区别在于,传入的参数不是 this 指针,而是一个被强制转化后的指针,编译器将 0 强制转化为对象指针传入函数,所以一个静态成员函数转化后是这样:
1 | extern float magnitude_7Point3dFv((Point3d*) 0) |
也正因为这样的转化,决定了我们所熟悉的静态成员函数的特性:
- 无需经由类对象调用,通过类名即可调用,因为无需传入具体的对象指针,0 指针只作为一个执行静态成员函数的绑定对象指针,除此之外没有任何功能
- 不能够直接存取类中的非静态成员,因为指针是 0,实际不指向任何对象实体
- 不能声明为 const,virtual 等
1.3 虚拟成员函数
虚成员函数在调用时被转化为经由 vptr 指向的虚函数表中的索引值调用:
1 | Point3d* ptr = new Point3d(); |
其中传入的 ptr 也是 this 指针,1 是该函数在虚函数表中的索引。
2 虚函数详解
之前我们已经了解了虚函数的一般模型:每一个类有一个虚函数表,其中存放该类中所有有作用的虚函数地址,然后每个对象内含一个成员变量 vptr,指向虚函数表。这一节中我们根据不同继承情况,深入了解该模型内部原理。
2.1 单一继承
任何情况下,一个 class 只会有一个 virtual table 。每一个 table 内含其对应的 class object 中所有 active virtual functions 函数实体的地址。这些 active virtual functions 包括:
- 这个 class 所定义的函数实体。它会改写 (overriding) 一个可能存在的 base class virtual function 实体
- 继承自 base class 的函数实体。这是在 derived class 决定不改写 base class virtual function 时才会出现的情况
- 一个纯虚函数调用(
pure_virtual_called())实体,它既可以扮演纯虚函数的空间占用者,也可以当作执行期的异常处理函数,当调用一个基类中的纯虚函数(即未被定义)时,会抛出异常并终止程序
单一继承情况下的虚函数表布局如下图:
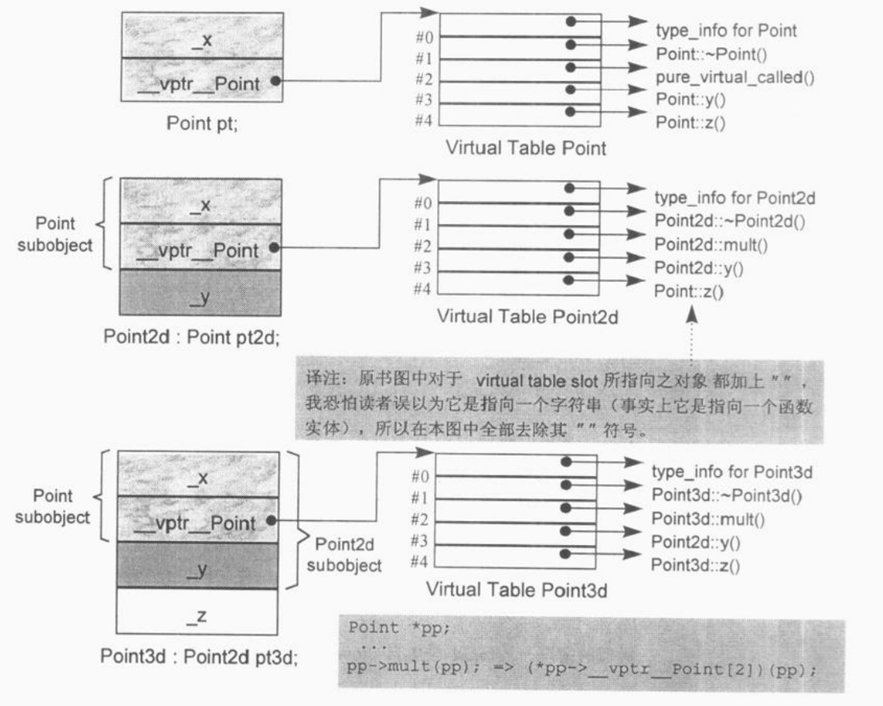
可以看到 Point2d 继承自 Point 类,重写的函数会覆盖基类虚函数,比如析构函数,以及在 Point2d 中实现的纯虚函数等,而没有重写的函数则直接复制基类虚函数表中该函数的地址,比如 Point::z() 函数。
回顾上一节提到的虚函数在编译时的转化,假设现在有如下调用:
1 | ptr->z(); |
则会被编译器转化为:
1 | (*ptr->vptr[4]) (ptr); |
于是这样的形式就可以提供给程序足够的信息,使其在执行期知道调用哪一个函数实体,因为:
- 虽然不知道 ptr 指向的具体对象类型,但是我们知道经由 ptr 可以访问到该对象的 vptr,从而访问到类的虚函数表
- 虽然不知道哪一个函数实体 z() 会被调用,但是所有类的 z() 函数实体地址都放在虚函数表中下标为 4 的地方
这正是指针和虚函数所支持的多态的内部原理之一。在一个单一继承体系中,这样的机制的行为十分良好,不但有效率而且很容易塑造出模型来。但是在多重继承和虚拟继承之中,就没有这么简单了。
2.2 多重继承
在多重继承之下,一个 derived class 内含 n 个虚函数表,n 表示上一层基类数目,其中第一个基类子对象指向的表为主要表格,其他的为次要表格,第一个基类的虚函数和派生类自己的虚函数都放在主要表格中。针对每一个虚函数表,派生类对象中都有对应的 vptr,当我们将一个派生类对象指定给第一个基类或者派生类的指针时,处理的是主要表格,其他情况处理的是次要表格。
多重继承情况下,虚函数表布局如下图:
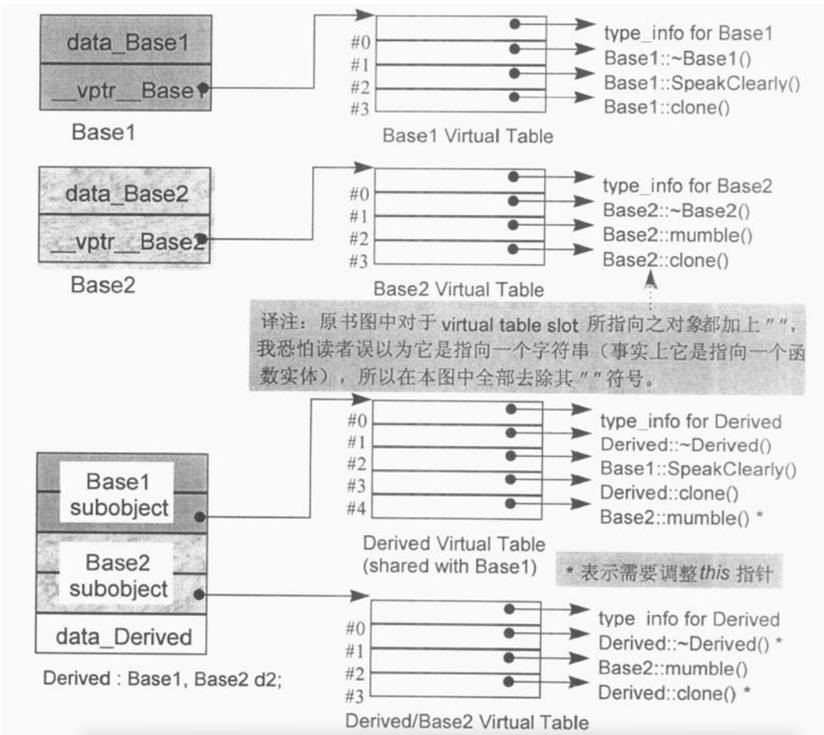
上图中的 * 表示需要调整 this 指针,当我们将派生类对象指定给第二个或之后的基类指针时,会存在一些需要调整 this 指针以支持正确的虚函数的情况,一般来说有以下三种情况(对应上面三个星号):
- 第一种情况:通过指向第二个基类的指针调用派生类的虚函数:
1 | Base2 *ptr = new Derived; |
上面的代码中 ptr 首先会被编译器调整至指向基类对象中的第二个基类子对象,编译器的调整代码如下:
1 | Derived *temp = new Derived; |
这样才能保证后续正确地访问或调用与第二个基类有关的成员和方法。但接下来的 delete ptr 需要调用析构函数,此时需要将 ptr 再向后调整至指向派生类对象起始地址,才能正确执行析构函数删除整个派生类对象。
- 第二种情况:通过一个指向派生类的指针,调用第二个基类中一个继承而来的虚函数,在这种情况派生类指针需要调整至指向第二个基类子对象
1 | Derived *pder = new Derived; |
- 第三种情况发生于一个语言扩充性质之下:允许一个 virtual function 的返回值类型有所变化,可能是 base type,也可能是 publicly derived type。这一点可以通过上图中的 clone() 函数说明,clone() 函数的派生版本返回一个派生类对象,默默地改写了两个基类函数实体,当我们通过第二个基类指针调用 clone() 函数时,需要调整 this 指针:
1 | Base2 *pb1 = new Derived; |
当进行 pb1->clone() 时,pb1 会被调整指向派生类对象的起始地址,于是会调用 clone() 函数的派生版本,它会传回一个新的派生类对象,当该对象被指定给第二个基类的指针时,需要调整以指向第二个基类子对象。
2.3 虚拟继承
虚拟继承的情况非常复杂,即使只有唯一的一个虚基类,他们的关系也不会像单一继承情况那样简单,因为虚基类和派生类不再相符,两者之间同样需要进行 this 指针转化。
当一个 virtual base class 从另一个 virtual base class 派生而来,并且两者都支持 virtual functions 和 nonstatic data members 时,编译器对于 virtual base class 的支持简直就像进了迷宫一样。总之一个建议是,不要在虚基类中声明非静态成员变量。
3 内联函数的背后工作
下表对比了不同类型成员函数的执行效率:

可以看到内联函数的效率占据绝对优势。在以往的学习中我们被告知,inline 函数将会在被调用的时候在调用处产生函数实体,这个操作称为扩展,即把内联函数代码扩展到调用处替换函数调用代码。
但实际上不是所有声明为 inline 的函数都能成为内联函数,inline 只是一种请求,只有这个请求被接受才会在函数调用处扩展 inline 代码。那么编译器如何决定是否接受这个请求呢?
编译器有一套复杂的算法来决定是否将函数认定为 inline,通常是计算 assignments、function calls、virtual function calls 等操作的次数。每个操作(表达式)种类有一个权值,而 inline 函数的复杂度就以这些操作的总和来决定。当其执行成本比一般的函数调用及返回机制所带来的负荷低,就被认定为 inline。
一般而言,处理一个 inline 函数包括以下两个阶段:
- 分析函数定义,以决定是否认定为 inline,如果函数因其复杂度,或因其建构问题,被判断为不可成为 inline,则它会被转为一个 static 函数,并在被编译模块内产生对应的函数定义。
- 真正的 inline 函数扩展操作是在调用的那个地方进行,这会带来参数的求值操作以及临时性对象的管理问题,接下来具体讨论。
3.1 有副作用的参数
inline 函数是如何被扩展的?下面一个例子可以说明问题,假设有如下内联函数:
1 | inline int min(int i, int j) |
下面是三个调用操作:
1 | int minval; |
以上三个调用会被扩展为:
1 | /**(1)**/minval = val1 < val2 ? val1 : val2; |
第(3)个调用把函数调用作为参数传入 inline 函数,这可能导致实际参数的多次求值操作,因此被认为是有副作用的参数,所以在扩展时使用了临时变量。而传入常量则会直接执行表达式,并将内联函数扩展为赋值操作。
3.2 局部变量
如果我们修改 inline 函数,引入局部变量:
1 | inline int min(int i, int j) |
然后调用:
1 | int minval; |
则会被扩展为:
1 | int min_lv_minval = val1 < val2 ? val1 : val2; |
inline 函数中的局部变量会被保留,并产生一个拥有唯一编码名字的临时变量。如果 inline 函数在同一个 scope 中被调用多次,那么每次都会产生一组名字不同的临时变量。
inline 函数中的局部变量,再加上有副作用的参数,可能会导致大量临时性对象的产生。特别是它被调用多次的时候,例如:
1 | minval = min(val1, val2) + min(foo(), foo() + 1); |
会被扩展为:
1 | // 为局部变量产生的临时变量 |
内联函数对于封装提供了一种必要的支持,可以有效存取封装于 class 中的 nonpublic 数据。它同时也是 C 程序中大量使用的#define (前置处理宏)的一个安全代替品,特别是如果宏中的参数有副作用的话。然而一个 inline 函数如果被调用太多次的话,会产生大量的扩展码,使程序的大小暴涨,并且由于参数带有副作用或者 inline 函数中有局部变量,会产生大量临时对象,编译器无法将它们移除。此外,inline 中再有 inline,可能会使一个表面上看起来简单的 inline 因其连锁复杂度而没办法扩展开来。对于既要安全又要效率的程序, inline 函数提供了一个强而有力的工具。然而,与 non-inline 函数比起来,它们需要更加小心地处理。