标准的 STL 关联式容器分为 set(集合) / map(映射表)两大类,以及这两大类的衍生体 multiset(多键集合)和 multimap(多键映射表)。这些容器的底层机制均以 RB-tree(红黑树)或hash table(哈希表)完成。
1 红黑树
红黑树是 C++ STL 唯一实现的树状结构,是所有关联式容器的底层容器,关于红黑树的理论知识可以查看【数据结构】二叉树第三部分。
1.1 红黑树节点
STL 中红黑树的的节点设计采用了结构和数值分离的方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
struct _Rb_tree_node_base
{
typedef _Rb_tree_Color_type _Color_type;
typedef _Rb_tree_node_base* _Base_ptr;
_Color_type _M_color;
_Base_ptr _M_parent;
_Base_ptr _M_left;
_Base_ptr _M_right;
static _Base_ptr _S_minimum(_Base_ptr __x)
{
while (__x->_M_left != 0) __x = __x->_M_left;
return __x;
}
static _Base_ptr _S_maximum(_Base_ptr __x)
{
while (__x->_M_right != 0) __x = __x->_M_right;
return __x;
}
};
template <class _Value>
struct _Rb_tree_node : public _Rb_tree_node_base
{
typedef _Rb_tree_node<_Value>* _Link_type;
_Value _M_value_field;
};
|
1.2 红黑树迭代器
为了更大的弹性, SGI 将 RB-tree 迭代器也实现为两层,下图所示的便是双层节点结构和双层迭代器结构之间的关系:
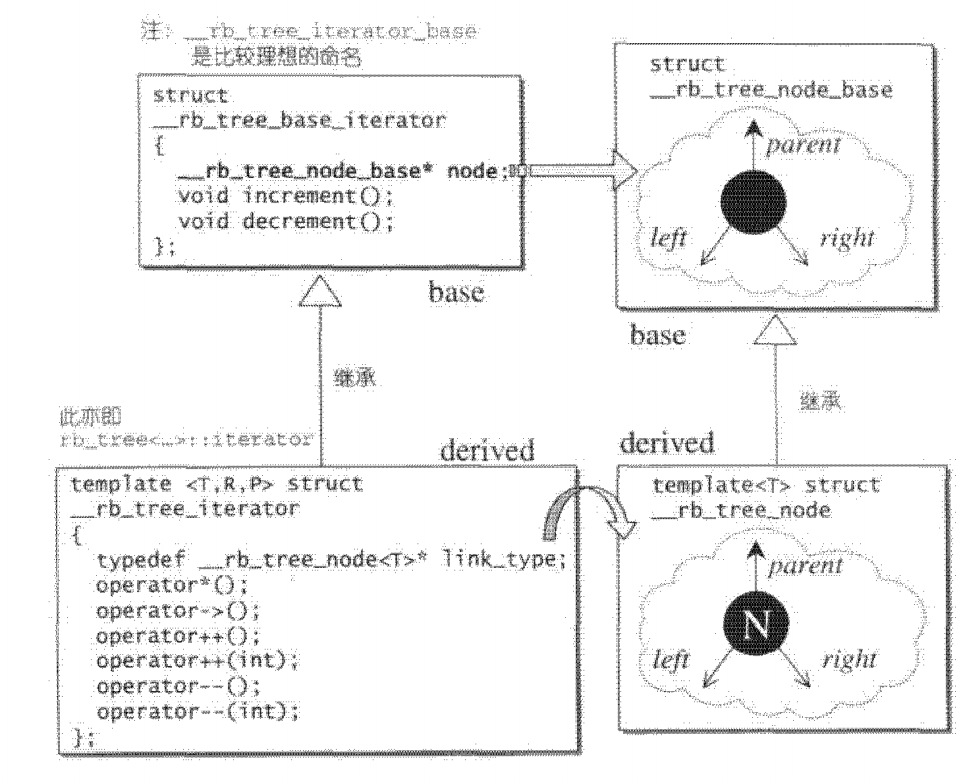
RB-tree 迭代器属于双向迭代器,不具备随机定位能力,其提领操作和成员访间操作与 list 十分近似,较为特殊的是其前进和后退操作。参见源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
|
struct _Rb_tree_base_iterator
{
typedef _Rb_tree_node_base::_Base_ptr _Base_ptr;
typedef bidirectional_iterator_tag iterator_category;
typedef ptrdiff_t difference_type;
_Base_ptr _M_node;
void _M_increment()
{
if (_M_node->_M_right != 0) {
_M_node = _M_node->_M_right;
while (_M_node->_M_left != 0)
_M_node = _M_node->_M_left;
}
else {
_Base_ptr __y = _M_node->_M_parent;
while (_M_node == __y->_M_right) {
_M_node = __y;
__y = __y->_M_parent;
}
if (_M_node->_M_right != __y)
_M_node = __y;
}
}
void _M_decrement()
{
if (_M_node->_M_color == _S_rb_tree_red &&
_M_node->_M_parent->_M_parent == _M_node)
_M_node = _M_node->_M_right;
else if (_M_node->_M_left != 0) {
_Base_ptr __y = _M_node->_M_left;
while (__y->_M_right != 0)
__y = __y->_M_right;
_M_node = __y;
}
else {
_Base_ptr __y = _M_node->_M_parent;
while (_M_node == __y->_M_left) {
_M_node = __y;
__y = __y->_M_parent;
}
_M_node = __y;
}
}
};
template <class _Value, class _Ref, class _Ptr>
struct _Rb_tree_iterator : public _Rb_tree_base_iterator
{
typedef _Value value_type;
typedef _Ref reference;
typedef _Ptr pointer;
typedef _Rb_tree_iterator<_Value, _Value&, _Value*>
iterator;
typedef _Rb_tree_iterator<_Value, const _Value&, const _Value*>
const_iterator;
typedef _Rb_tree_iterator<_Value, _Ref, _Ptr>
_Self;
typedef _Rb_tree_node<_Value>* _Link_type;
_Rb_tree_iterator() {}
_Rb_tree_iterator(_Link_type __x) { _M_node = __x; }
_Rb_tree_iterator(const iterator& __it) { _M_node = __it._M_node; }
reference operator*() const { return _Link_type(_M_node)->_M_value_field; }
#ifndef __SGI_STL_NO_ARROW_OPERATOR
pointer operator->() const { return &(operator*()); }
#endif
_Self& operator++() { _M_increment(); return *this; }
_Self operator++(int) {
_Self __tmp = *this;
_M_increment();
return __tmp;
}
_Self& operator--() { _M_decrement(); return *this; }
_Self operator--(int) {
_Self __tmp = *this;
_M_decrement();
return __tmp;
}
};
inline bool operator==(const _Rb_tree_base_iterator& __x,
const _Rb_tree_base_iterator& __y) {
return __x._M_node == __y._M_node;
}
inline bool operator!=(const _Rb_tree_base_iterator& __x,
const _Rb_tree_base_iterator& __y) {
return __x._M_node != __y._M_node;
}
#ifndef __STL_CLASS_PARTIAL_SPECIALIZATION
inline bidirectional_iterator_tag
iterator_category(const _Rb_tree_base_iterator&) {
return bidirectional_iterator_tag();
}
|
2 set & map
set 的所有元素都会根据元素的键值自动排序。set 的元素不像 map 那样可以同时拥有 key 和 value,set 元素的 key 就是 value,value 就是 key,set不允许有两个相同的元素。
map 的所有元素都会根据元素的键值自动排序。map 的所有元素都是 pair,同时拥有 key 和 value。pair 的第一元素为 key,第二元素为 value。map不允许有两个相同的键值。如果通过map的迭代器改变元素的键值,这样是不行的,因为 map 元素的键值关系到 map 元素的排列规则。任意改变 map 元素键值都会破坏 map 组织。如果修改元素的实值,这是可以的,因为 map 元素的实值不影响 map 元素的排列规则。
3 multiset & multimap
multiset 和 multimap 的特性以及用法和 set 与 map 完全相同,唯一的差别在于它们允许键值重复,因此它的插入操作采用的是底层机制 RB-tree 的insert_equal() 而非 insert_unique()。
4 hash table
hash table 是 STL 实现的另一种底层数据结构。之前的二叉搜索树具有对数平均时间表现,但这样的表现构造在一个假设上:输入数据有足够的随机性。hashtable 这种结构在插入、删除、查找具有“常数平均时间”,而且这种表现是以统计为基础,不需依赖元素的随机性。
hash table 底层数据结构为分离连接法的 hash 表,如下所示:
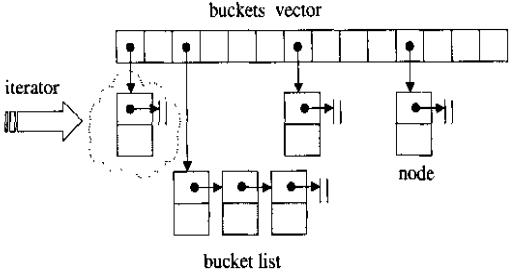
hash table 中的 buckets 使用的是vector数据结构,当插入一个元素时,先利用 hash 函数,对元素的 key 进行映射(常见的为取模),找到该插入哪个 bucket 内,然后遍历该 bucket 指向的链表,如果有相同的元素,就返回;否则的话就将该元素插入到该链表的头部。当然,如果是 multi 版本的话,是可以插入重复元素的,此时插入过程为:当插入一个元素时,先利用 hash 函数,对元素的 key 进行映射,找到该插入哪个 bucket 内,然后遍历该 bucket 指向的链表,如果有相同的元素,就将新节点插入到该相同元素的后面;如果没有相同的元素,产生新节点,插入到链表头部。
对应的查询过程也是同理。此外,当调用成员函数 clear() 后,buckets vector 并未释放空间,仍保留原来大小,只是删除了 buckets 所连接的链表。
5 hash_set & hash_map
hash_set 和 hash_map 以 hashtable 为底层结构,由于 RB-tree 有自动排序功能而 hash table 没有,反映出来的结果就是,set 和 map的元素有自动排序功能而hash_set 和 hash_map 没有。
6 hash_multiset & hash_multimap
hash_multiset 和 hash_multimap 的特性与 multiset 和 multimap 完全相同,唯一的差别在于它们的底层机制是 hash table,因此,hash_multiset 和 hash_multimap 的元素是不会自动排序的。
7 unordered_set & unordered_map
unordered_set 和 unordered_map 是 C++11 标准新增的容器,底层同样使用 hash table 实现,但一般来说效率比 hash_set 和 hash_map 更高,原因在于二者 rehash 实现不同。因此 hash_set 和 hash_map 基本已弃用。
8 红黑树和 hash table 对比
虽然大多数情况下 hash table 实现的 map 都会比红黑树实现的 map 查找快,但不是绝对的,因为冲突过多的话,可能耗费时间比 map 还要多。
另外,hash table 的实现决定了其使用的空间会比实际数据空间大。红黑树初始化时,节点只需要一个,后续的插入只是插入新的节点,但是哈希表初始化时就不是那么简单了,哈希表初始化时需要申请一个数组,数组的每个元素都指向一条链表,所以初始化时需要申请很多内存,相比于红黑树,的确更耗时。
相对于红黑树,hash table的优点很明显:插入,查找,删除复杂度为常数时间,大规模查询时,性能差距更为明显。
但相比于hash table,平衡树也是有优点的:
- 首先,尽管我们都说 hash 查找插入删除复杂度是常数时间,但这仅仅是个统计上的概念,最差情况下,也是会达到 O(n),而红黑树最差的情况下也是 O(logn);
- 其次,hash table 实际上是空间换时间的做法,空间越小,操作的时间复杂度越大,操作时间越不稳定,而平衡树则稳定很多;
- 还有一个就是序,红黑树是查找树,因此中序遍历的结果就是排好序的。这就使得其在范围查找方面性能优秀,而 hash 却需要遍历全部数据,之后统计才能得出范围查找的结果。另外,如果你知道一个元素在树中的位置,和它大小相近的元素也在它周围,这就使得获取相近元素的时间很少。另外,我们知道,中序遍历的时间复杂度也只是 O(n),这个性质非常有用。
map 和 unordered_map 的使用场景基本上就是根据上述各自的特性决定了:
- map 一般就是用在数据量小于1000或者对内存使用要求比较高的情况下。因为 hash table 需要申请的空间比较大,而红黑树则是新增一个节点就申请一个节点的空间。
- 如果数据量大的话并且需要频繁查找的话,就可以使用 hash table 实现的 map 了。这个时候内存已经不是主要的问题所在,而是查找时间了,这种情况下 hash table 的查找速度是常数而红黑树是 O(logN),对于后者,1024个数据最坏情况下要10次比较,在频繁查找的情况下这种时间耗费是很大的。